Complement for 3b1b’s Diffusion Models Video 扩散模型学习笔记 (更新中)
Machine-Learning
CN-blogs
I’m learning this, updating notes here.
1 Introduction
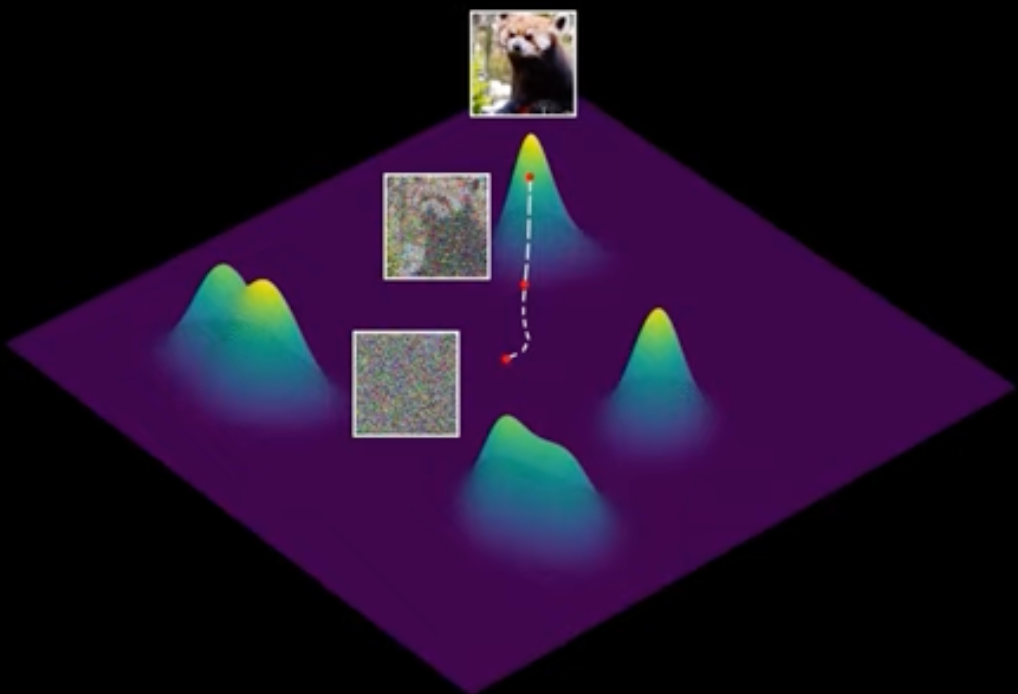
- 有意义的图片在 Image Space 中的分布过于复杂而无法表示.
1.1 Core Ideas in 3b1b’s Video
- 引入 Image Space, 这个 Space 大部分地方的图片都没有意义, 极少部分地方的图片是有意义的 (3b1b 视频中用 Spiral 来表示)
- 生成图片的问题可重述为: 从 Image Space 中任意位置出发, 将其移动到有意义的图片位置.
- 训练范式的思考过程:
- 直接在 Figure 1 中梯度上升找到有意义的图像. 但如何知道概率标量场 / 梯度场 (“Score function” [2]) 呢?
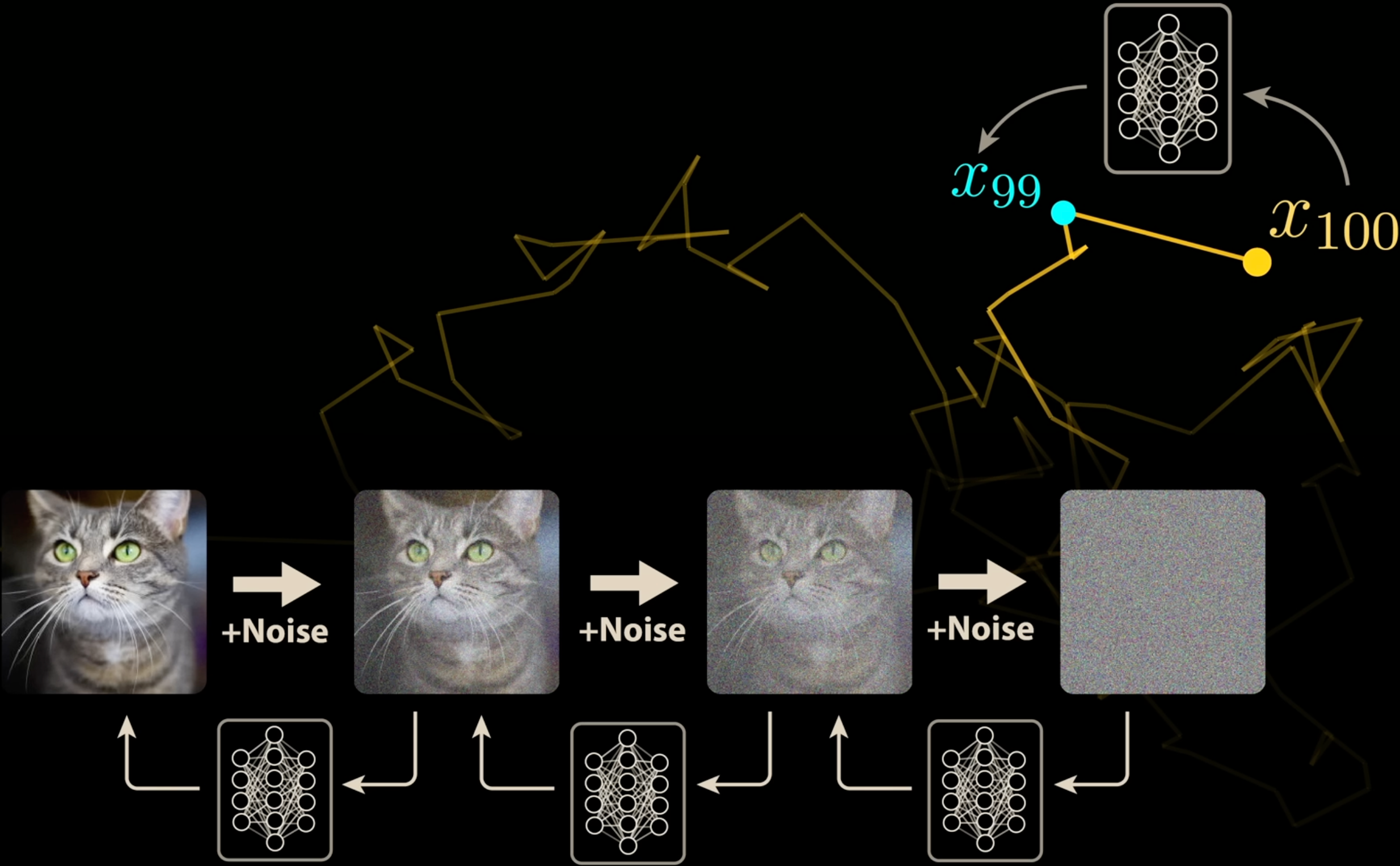
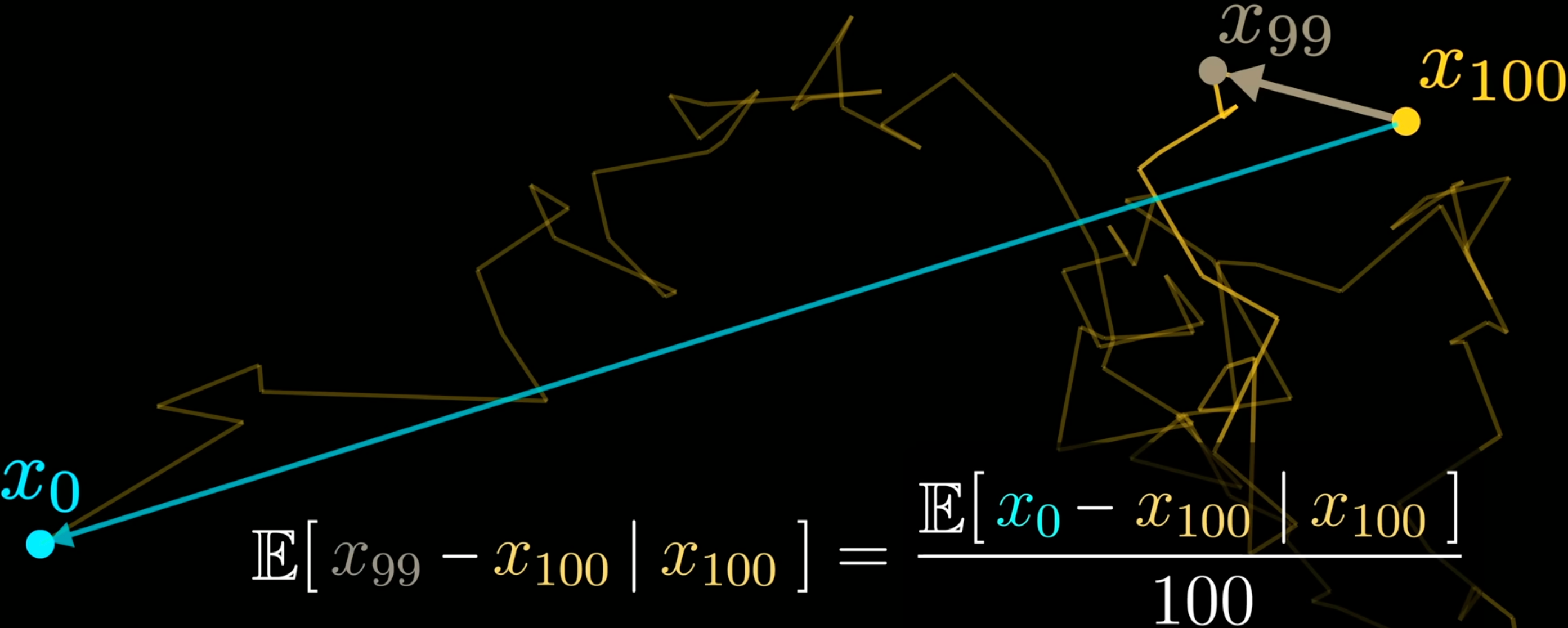
- 为了学到这个梯度场, 用已知有意义的图片不断加噪声 (相当于该图片点在 Image Space 上做 Brownian Motion), 然后设计一个神经网络来逐步 (“One-step”) 学习反过来的过程 Figure 2 . 但这在统计意义上相当于直接用起点和终点来训练 (Figure 3), 用起始点而不用中间点来训练的好处是降低了训练数据的 Variance 的影响.
- 为了学习到 “More refined structure of the spiral”, 不同程度的 Brownian Motion 需要不同的神经网络进行处理, 也可以理解为给神经网络加入 \(t\) 参数 (表示游走的时间长度) Figure 4.
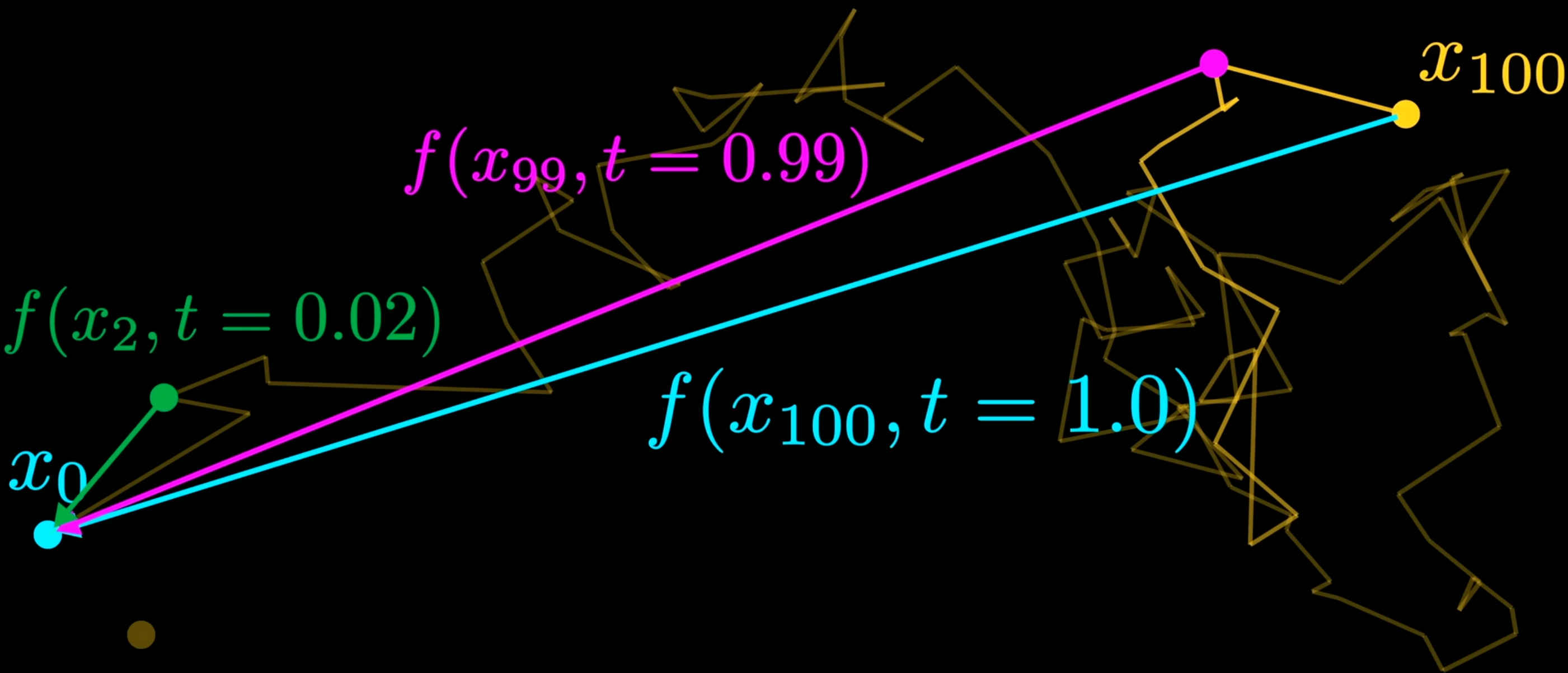
1.2 My question
- 如何根据用户的文字描述来生成对应意义的图片? 跟编码和 Cross Attention 有关?
- 神经网络能学习到 Brownian Motion 的逆过程? Why it works?
- “给神经网络加入 \(t\) 参数”, 具体如何操作?
References
1.
2.
Song Y, Sohl-Dickstein J, Kingma DP, Kumar A, Ermon S, Poole B (2020) Score-based generative modeling through stochastic differential equations. CoRR abs/2011.13456