NN Architectures 常见网络架构
MobileNet
Task Objective 任务目标
- 识别东西是什么
- 将东西的位置框起来
- 模型需要轻量和简洁以便在 edge 设备上运行
- 在保持模型准确度的前提下降低模型参数量的方法有两种:
- Quantization 量化
- 直接设计小模型训练 (MobileNetv1 采用这种方法)
- 在保持模型准确度的前提下降低模型参数量的方法有两种:
MobileNetv1
其实就是一个 CNN, 只不过对卷积操作做了改进, 用 Depthwise Separable Convolution 代替了普通的卷积操作.
DSC 深度可分离卷积
我们直接举例说明 DSC (Depthwise Separable Convolution) 如何减少计算量:
- 参数:
- Input 输入信息: \((7\times 7) \times 8 = 392\) (\(8\) 个 channel).
- Output 输出信息: 同上.
- Filter 卷积核:
- 平面 (2D) 大小: \(3 \times 3 = 9\).
- 立体 (3D) 大小: \((3\times 3) \times 8 = 72\).
- 张量 (4D) 大小: \((3\times 3) \times 8 \times 8 = 576\). (最后的 \(8\) 是卷积核个数 (= 输出通道数), 注意 HWCN 规范).
- Figure fig-normal-conv 中每个「立体核」都会对 Input 进行扫描, 姑且将「闪」一下称为一次「快照」.
- Stride = 1 (
s1). - Padding = 1 (Figure fig-normal-conv 的灰色部分).
- 常规卷积层 (见 Figure fig-normal-conv):
- 参数量 = 一个立体核参数量 + 有几个立体核 \(= (72+1) \times 8 = 584\) (别忘了每个卷积核还有有一个 bias 参数).
- MAC1 = 「闪」一次的 MAC \(\times\)「闪」的总次数 \(= 72 \times 392 = 28224\).
- FLOPs = MAC \(\times 2 = 56448\).
1 算 MAC 的时候这样思考: 每「闪」一下都算了 \(72\) 次乘法和 \(71\) 次加法, 哦不对! 最后还要加 bias, 所以加法也是 \(72\) 次 (即 MAC=72); 而输出的每个「小方块」都对应一次「快照」! 这两个数乘一下就是总 MAC 数了.
- DSC (见 Figure fig-dsc):
- 参数量
- Depthwise 部分 \(= (9+1) \times 8 = 80\).
- Pointwise 部分 \(= (8+1) \times 8 = 72\).
- 总共 \(80 + 72 = 152\).
- MAC
- Depthwise 部分 \(= 9 \times 392 = 3528\).
- Pointwise 部分 \(= 8 \times 392 = 3136\).
- 总共 \(3528 + 3136 = 6664\) (比常规卷积小了 \(4\) 倍多!).
- FLOPs = MAC \(\times 2 = 13328\).
- DSC 相当于将 channel 之间和 spatial 之间的信息混合方式分开训练,
- 参数量



Vision Transformer
test
TBD
YOLO
本章基本上是 YOLO V1 Bilibili 讲解 的笔记, 可以直接看视频学习.
Task Objective 任务目标
- 识别东西是什么
- 将东西的位置框起来
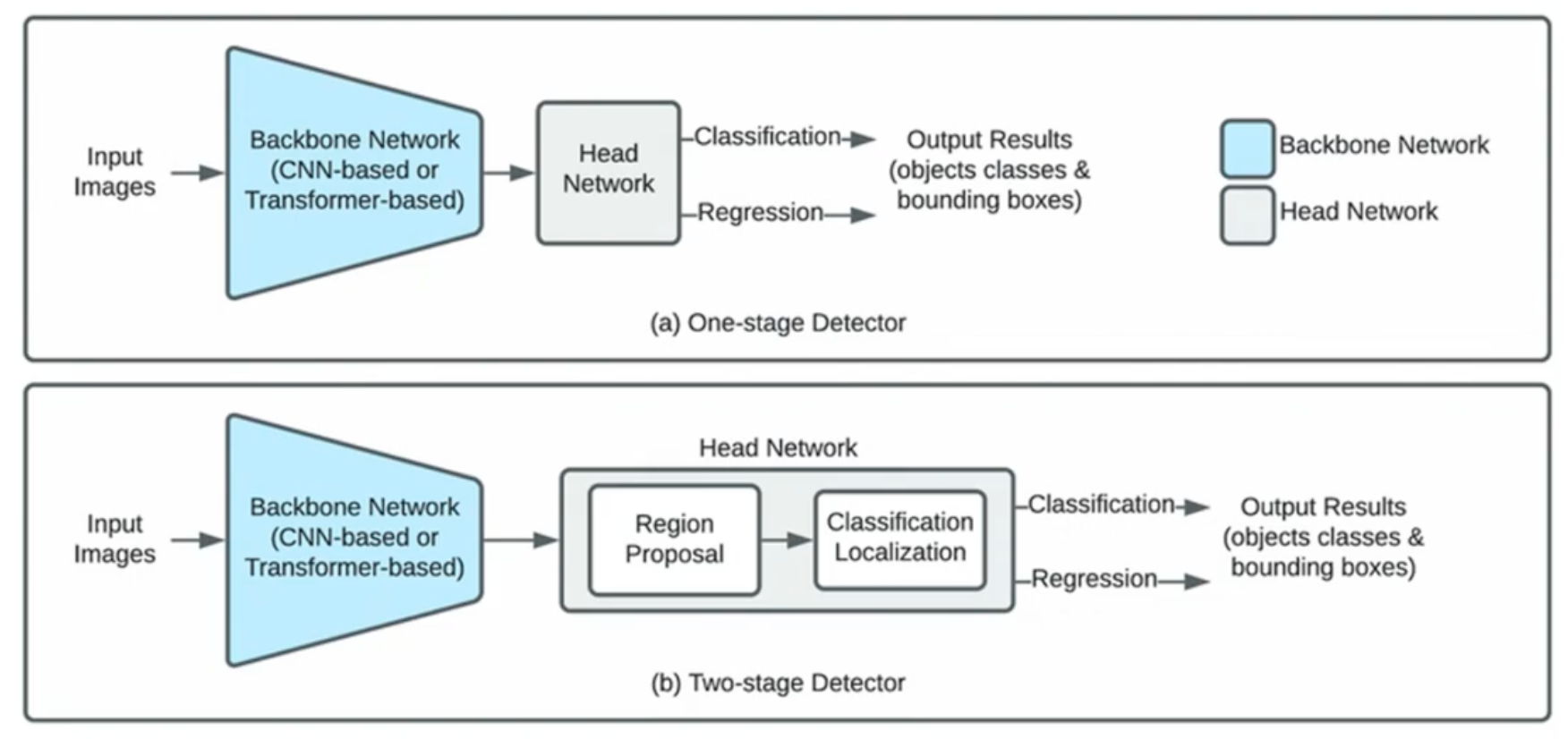
两类方法
解决这个问题的方法有两类:
- One-stage: 推理速度快, 可实时
- E.g., YOLO, SSD, RetinaNet
- Two-stage: 准确率高
- Region Proposal 候选区: 先从图片中提取出可能包含目标的 1000-2000 个区域, 然后对每个候选区进行目标对象识别操作.
- E.g., Faster R-CNN, Mask R-CNN, Cascade R-CNN

损失函数
YOLO V1
Network Structure 网络结构
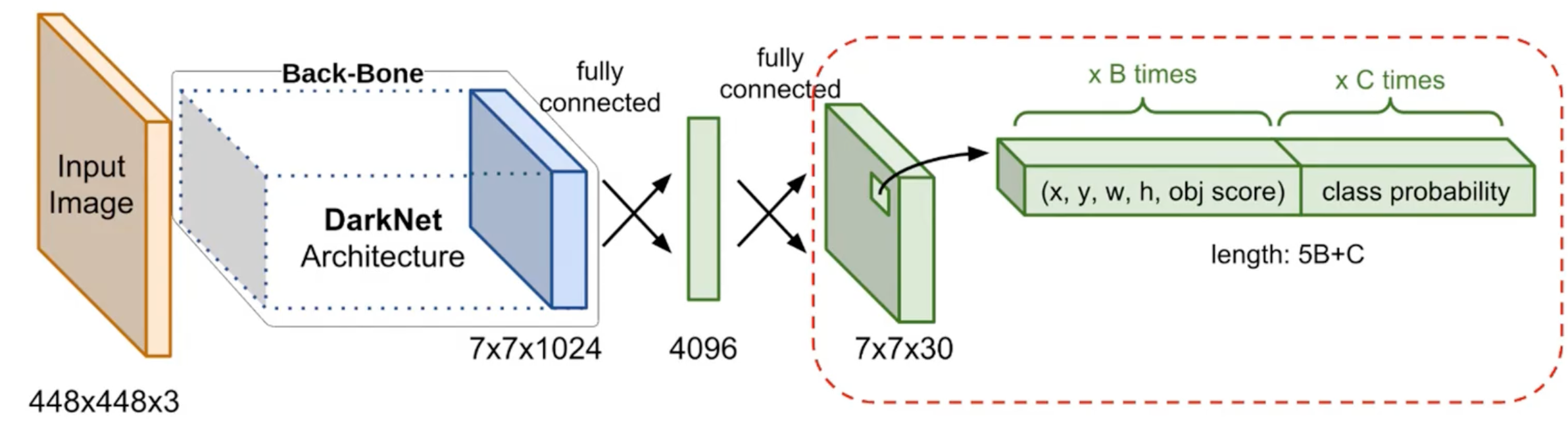
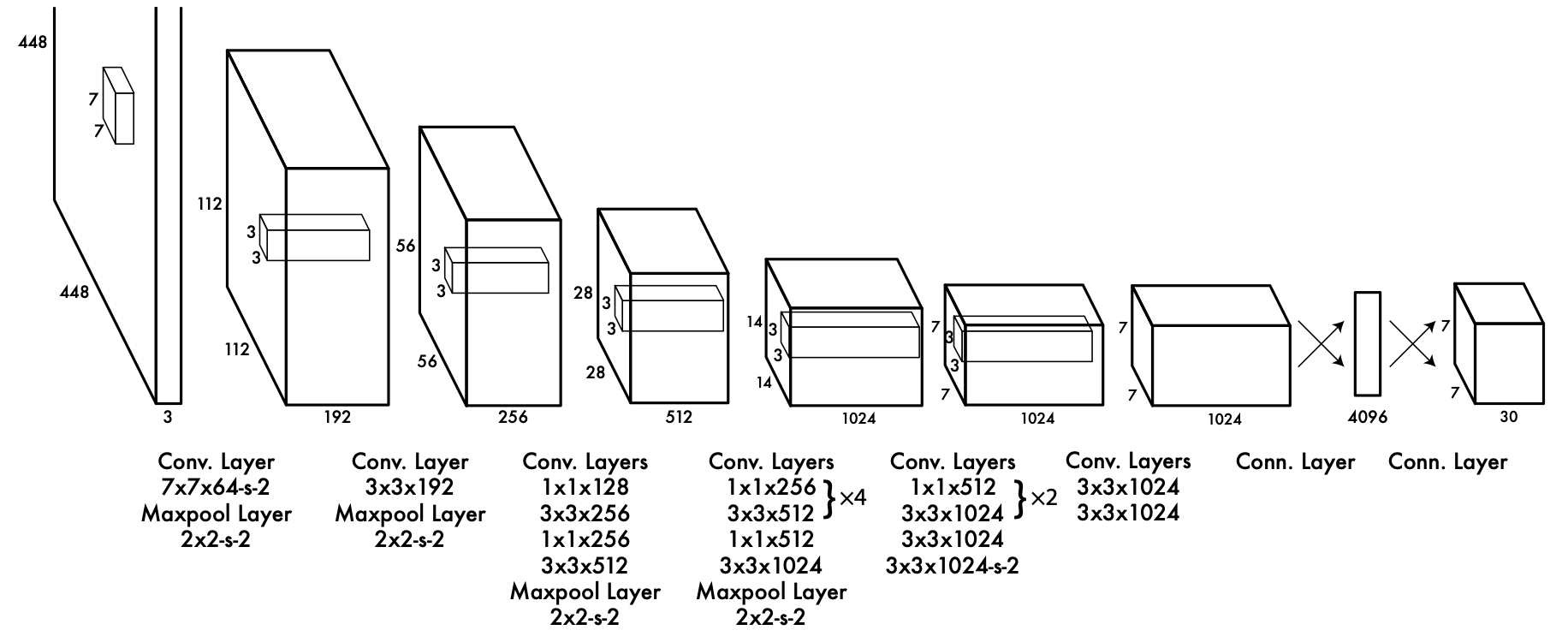
说明:
Figure fig-yolov1-back-bone:
-s-2表示 stride 步长为 2.输入输出:
- 输入是一张正方形的图片 (长宽像素各为 \(448\), 有 3 个通道: RGB).
- 输出的 tensor 大小为 \(7 \times 7 \times 30\)
Label Tensor 标签张量
MSCOCO 数据集需要先转换成另外一种形式 (Figure fig-yolo-v1-data-labeling) 再喂给 TOLO V1 神经网络 (即换一种形式打标签而已).
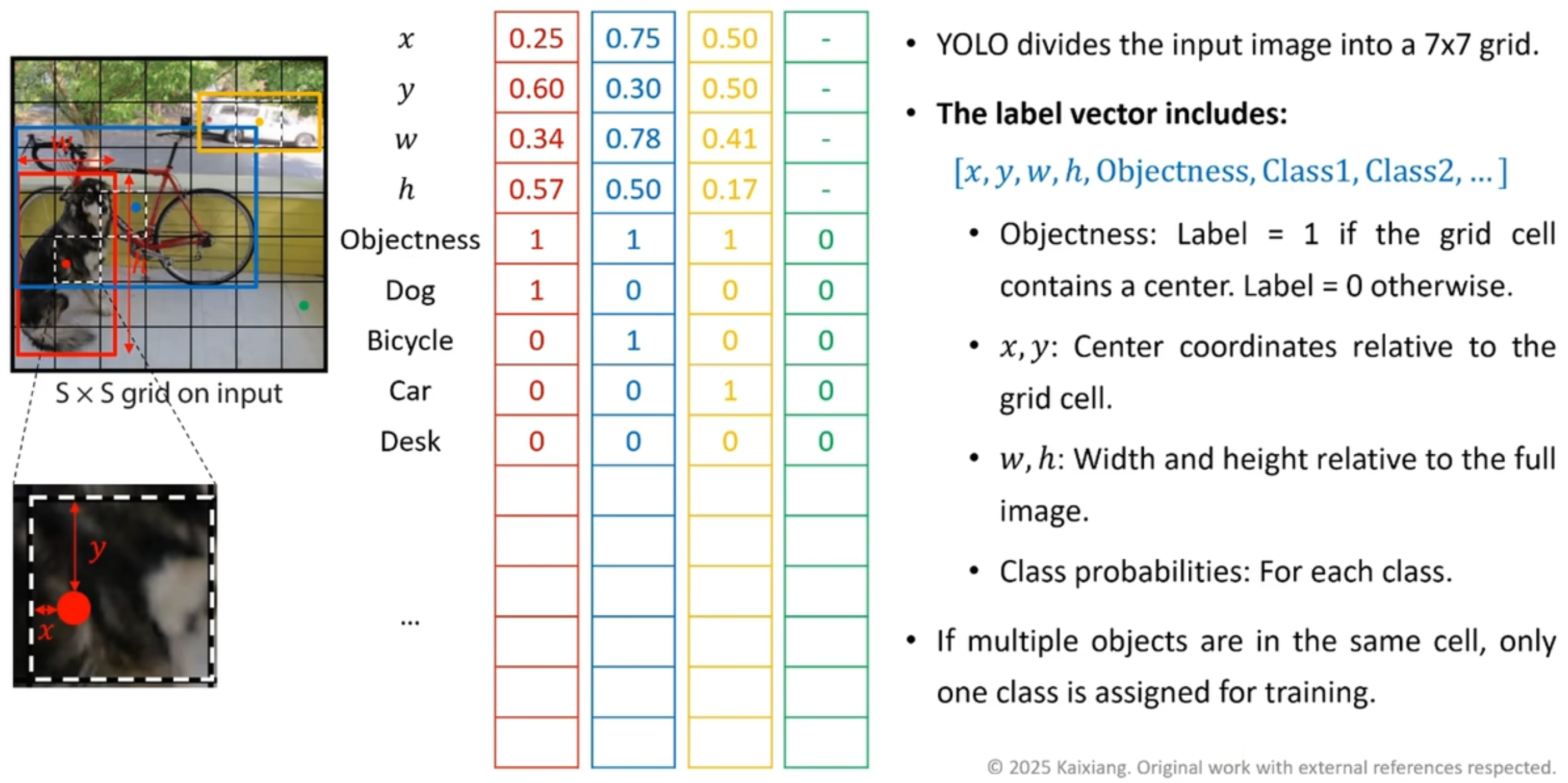
Figure 9: YOLO V1: \(S = 7\), 总共 每张图片都有 \(S \times S = 49\) 个 grid cell, 每一个 grid cell 都被一个 \(30 \times 1\) 的向量描述, 相当于一张图片都对应了一个 \(7 \times 7 \times 30\) 的 label tensor.
- Figure fig-yolov1-back-bone 中网络的输出也是一个 \(7 \times 7 \times 30\) 的 tensor, 但这是 Prediction Tensor 预测张量 (sec-prediction-tensor), 不能混为一谈.
如果有两个物体的中心点都落在同一个 grid cell 中, YOLO V1 只会保留其中一个.
Prediction Tensor 预测张量
TODO
References
[1]
A. AI, “Fundamental algorithm of convolution in neural networks.” Github.io, Feb. 2023. Available: https://animatedai.github.io. [Accessed: Jan. 03, 2026]
[2]
上下求索电子Er, “[YOLO V1] 数据标注和输出张量_哔哩哔哩_bilibili,” 2025, Available: https://www.bilibili.com/video/BV1gKwAeWEo4/?spm_id_from=333.788.player.switch&vd_source=42579e22289b6144ba0b2bdcf99834e3&p=3
[3]
J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection.” 2016. Available: https://arxiv.org/abs/1506.02640